Enterprise Apache Hadoop provides the fundamental data services required to deploy into existing architectures. These include security, governance and operations services, in addition to Hadoop’s original core capabilities for data management and data access. This post focuses on recent work completed in the open source community to enhance the Hadoop security component, with encryption and SSL certificates.
Last year I wrote a blog summarizing wire encryption options in Hortonworks Data Platform (HDP). Since that blog, encryption capabilities in HDP and Hadoop have expanded significantly.
One of these new layers of security for a Hadoop cluster is Apache Knox. With Knox, a Hadoop cluster can now be made securely accessible to a large number of users. Today, Knox allows secure connections to Apache HBase, Apache Hive, Apache Oozie, WebHDFS and WebHCat. In the near future, it will also include support for Apache Hadoop YARN, Apache Ambari, Apache Falcon, and all the REST APIs offered by Hadoop components.
Without Knox, these clients would connect directly to a Hadoop cluster, and the large number of direct client connections poses security disadvantages. The main one is access.
In a typical organization, only a few DBAs connect directly to a database, and all the end-users are routed through a business application that then connects to the database. That intermediate application provides an additional layer of security checks.
Hadoop’s approach with Knox is no different. Many Hadoop deployments use Knox to allow more users to make use of Hadoop’s data and queries without compromising on security. Only a handful of admins can connect directly to their Hadoop clusters, while end-users are routed through Knox.
Apache Knox plays the role of reverse proxy between end-users and Hadoop, providing two connection hops between the client and Hadoop cluster. The first connection is between the client and Knox, and Knox offers out of the box SSL support for this connection. The second connection is between Knox and a given Hadoop component, which requires some configuration.
This blog walks through configuration and steps required to use SSL for the second connection, between Knox and a Hadoop component.
SSL Certificates
SSL connections require a certificate, either self-signed or signed by a Certificate Authority (CA). The process of obtaining self-signed certificates differs slightly from how one obtains CA-signed certificates. When the CA is well-known, there’s no need to import the signer’s certificate into the truststore. For this blog, I will use self-signed certificates; however, wire encryption can also be enabled with a CA-signed certificate. Recently, my colleague Haohui Moi blogged about HTTPS with HDFS and included instructions for a CA-signed certificate.
SSL Between Knox & HBase
The first step is to configure SSL on HBase’s REST server (Stargate). To configure SSL, we will need to create a keystore to hold the SSL certificate. This example uses a self-signed certificate, and a SSL certificate used by a Certificate Authority (CA) makes the configuration steps even easier.
As user HBase (su hbase) create the keystore.
export HOST_NAME=`hostname`
keytool -genkey -keyalg RSA -alias selfsigned -keystore hbase.jks -storepass password -validity 360 -keysize 2048 -dname "CN=$HOST_NAME, OU=Eng, O=Hortonworks, L=Palo Alto, ST=CA, C=US" -keypass password
Make sure the common name portion of the certificate matches the host where the certificate will be deployed. For example, the self-signed SSL certificate I created has the following CN sandbox.hortonworks.com, when the host running HBase is sandbox.hortonworks.com.
“Owner: CN=sandbox.hortonworks.com, OU=Eng, O=HWK, L=PA, ST=CA, C=US
Issuer: CN=sandbox.hortonworks.com, OU=Eng, O=HWK, L=PA, ST=CA, C=US”
We just created a self-signed certificate for use with HBase. Self-signed certificates are rejected during SSL handshake. To get around this, export the certificate and put it in the cacerts file of the JRE used by Knox. (This step is unnecessary when using a certificate issued by a well known CA.)
On the machine running HBase, export HBase’s SSL certificate into a file hbase.crt:
keytool -exportcert -file hbase.crt -keystore hbase.jks -alias selfsigned -storepass password
Copy the hive.crt file to the Node running Knox and run:
keytool -import -file hbase.crt -keystore /usr/jdk64/jdk1.7.0_45/jre/lib/security/cacerts -storepass changeit -alias selfsigned
Make sure the path to cacerts file points to cacerts of JDK used to run Knox gateway.
The default cacerts password is “changeit.”
Configure HBase REST Server for SSL
Using Ambari or another tool used for editing Hadoop configuration properties:
<property>
<name>hbase.rest.ssl.enabled</name>
<value>true</value>
</property>
<property>
<name>hbase.rest.ssl.keystore.store</name>
<value>/path/to/keystore/created/hbase.jks</value>
</property>
<property>
<name>hbase.rest.ssl.keystore.password</name>
<value>password</value>
</property>
<property>
<name>hbase.rest.ssl.keystore.keypassword</name>
<value>password</value>
</property>
Save the configuration and re-start the HBase REST server using either Ambari or with command line as in:
sudo /usr/lib/hbase/bin/hbase-daemon.sh stop rest & sudo /usr/lib/hbase/bin/hbase-daemon.sh start rest -p 60080
Verify HBase REST server over SSL
Replace localhost with whatever is the hostname of your HBase rest server.
curl -H "Accept: application/json" -k https://localhost:60080/
It should output the tables in your HBase. e.g. name.
{“table”:[{"name":"ambarismoketest"}]}
Configure Knox to point to HBase over SSL and re-start Knox
Change the URL of the HBase service for your Knox topology in sandbox.xml to HTTPS e.g, ensure Host matches the host of HBase rest server.
<service>
<role>WEBHBASE</role>
<url>https://sandbox.hortonworks.com:60080</url>
</service>
Verify end to end SSL to HBase REST server via Knox
curl -H "Accept: application/json" -iku guest:guest-password -X GET 'https://localhost:8443/gateway/sandbox/hbase/'
Should have an output similar to below:
HTTP/1.1 200 OK
Set-Cookie: JSESSIONID=166l8e9qhpi95ty5le8hni0vf;Path=/gateway/sandbox;Secure;HttpOnly
Expires: Thu, 01 Jan 1970 00:00:00 GMT
Cache-Control: no-cache
Content-Type: application/json
Content-Length: 38
Server: Jetty(8.1.14.v20131031)
{“table”:[{"name":"ambarismoketest"}]}
SSL Between Knox & HiveServer
Create Keystore for Hive
As a Hive user (su hive) create the keystore.
The first step is to configure SSL on HiveServer2. To configure SSL create a keystore to hold the SSL certificate. The example here uses self-signed certificate. Using SSL certificate issued by a Certificate Authority(CA) will make the configuration steps easier by eliminating the need to import the signer’s certificate into the truststore.
On the Node running HiveServer2 run commands:
keytool -genkey -keyalg RSA -alias hive -keystore hive.jks -storepass password -validity 360 -keysize 2048 -dname "CN=sandbox.hortonworks.com, OU=Eng, O=Hortonworks, L=Palo Alto, ST=CA, C=US" -keypass password
keytool -exportcert -file hive.crt -keystore hive.jks -alias hive -storepass password -keypass password
Copy the hive.crt file to the Node running Knox and run:
keytool -import -file hive.crt -keystore /usr/jdk64/jdk1.7.0_45/jre/lib/security/cacerts -storepass changeit -alias hive
Make sure the path to cacerts file points to cacerts of JDK used to run Knox gateway. The default cacerts password is “changeit.”
Configure HiveServer2 for SSL
Using Ambari or other tool used for editing Hadoop configuration, ensure that hive.jks is in a location readable by HiveServer such as /etc/hive/conf
<property>
<name>hive.server2.use.SSL</name>
<value>true</value>
</property>
<property>
<name>hive.server2.keystore.path</name>
<value>/etc/hive/conf/hive.jks</value>
<description>path to keystore file</description>
</property>
<property>
<name>hive.server2.keystore.password</name>
<value>password</value>
<description>keystore password</description>
</property>
Save the configuration and re-start HiveServer2
Validate HiveServer2 SSL Configuration
Use Beeline & connect directly to HiveServer2 over SSL
beeline> !connect jdbc:hive2://sandbox:10001/;ssl=true beeline> show tables;
Ensure this connection works.
Configure Knox connection to HiveServer2 over SSL
Change the URL of the Hive service for your Knox topology in sandbox.xml to HTTPS e.g, ensure host matches the host of Hive server.
<service>
<role>Hive</role>
<url>https://sandbox.hortonworks.com:10001/cliservice</url>
</service>
Validate End to End SSL from Beeline > Knox > HiveServer2
Use Beeline and connect via Knox to HiveServer2 over SSL
beeline> !connect jdbc:hive2://sandbox:8443/;ssl=true;sslTrustStore=/var/lib/knox/data/security/keystores/gateway.jks;trustStorePassword=knox hive.server2.transport.mode=http;hive.server2.thrift.http.path=gateway/sandbox/hive
beeline> show tables;>
SSL Between Knox & WebHDFS
Create Keystore for WebHDFS
execute this shell script or set up environment vairables:
export HOST_NAME=`hostname`
export SERVER_KEY_LOCATION=/etc/security/serverKeys
export CLIENT_KEY_LOCATION=/etc/security/clientKeys
export SERVER_KEYPASS_PASSWORD=password
export SERVER_STOREPASS_PASSWORD=password
export KEYSTORE_FILE=keystore.jks
export TRUSTSTORE_FILE=truststore.jks
export CERTIFICATE_NAME=certificate.cert
export SERVER_TRUSTSTORE_PASSWORD=password
export CLIENT_TRUSTSTORE_PASSWORD=password
export ALL_JKS=all.jks
export YARN_USER=yarn
execute these commands:
mkdir -p $SERVER_KEY_LOCATION ; mkdir -p $CLIENT_KEY_LOCATION
cd $SERVER_KEY_LOCATION;
keytool -genkey -alias $HOST_NAME -keyalg RSA -keysize 2048 -dname "CN=$HOST_NAME,OU=hw,O=hw,L=paloalto,ST=ca,C=us" -keypass $SERVER_KEYPASS_PASSWORD -keystore $KEYSTORE_FILE -storepass $SERVER_STOREPASS_PASSWORD
cd $SERVER_KEY_LOCATION ; keytool -export -alias $HOST_NAME -keystore $KEYSTORE_FILE -rfc -file $CERTIFICATE_NAME -storepass $SERVER_STOREPASS_PASSWORD
keytool -import -trustcacerts -file $CERTIFICATE_NAME -alias $HOST_NAME -keystore $TRUSTSTORE_FILE
Also, import the certificate to the truststore used by Knox which is the JDK’s default cacerts file.
keytool -import -trustcacerts -file certificate.cert -alias $HOST_NAME -keystore /usr/lib/jvm/jre-1.7.0 openjdk.x86_64/lib/security/cacerts
Make sure to point the path to cacerts for the JDK used by Knox in your deployment.
Type yes when the asked to add the certificate to the truststore.
Configure HDFS for SSL
Copy example ssl-server.xml and edit it to use the ssl configuration created in previous step.
cp /etc/hadoop/conf.empty/ssl-server.xml.example /etc/hadoop/conf/ssl-server.xml
And and make sure the following properties are set in /etc/hadoop/conf/ssl-server.xml:
<configuration>
<property>
<name>ssl.server.truststore.location</name>
<value>/etc/security/serverKeys/truststore.jks</value>
</property>
<property>
<name>ssl.server.truststore.password</name>
<value>password</value>
</property>
<property>
<name>ssl.server.truststore.type</name>
<value>jks</value>
</property>
<property>
<name>ssl.server.keystore.location</name>
<value>/etc/security/serverKeys/keystore.jks</value>
</property>
<property>
<name>ssl.server.keystore.password</name>
<value>password</value>
</property>
<property>
<name>ssl.server.keystore.type</name>
<value>jks</value>
</property>
<property>
<name>ssl.server.keystore.keypassword</name>
<value>password</value>
</property>
</configuration>
Use Ambari to set the following properties in core-site.xml.
hadoop.ssl.require.client.cert=false
hadoop.ssl.hostname.verifier=DEFAULT_AND_LOCALHOST
hadoop.ssl.keystores.factory.class=org.apache.hadoop.security.ssl.FileBasedKeyStoresFactory
hadoop.ssl.server.conf=ssl-server.xml
Use Ambari to set the following properties in hdfs-site.xml.
dfs.http.policy=HTTPS_ONLY
dfs.datanode.https.address=workshop.hortonworks.com:50475
The valid values for dfs.http.policy are HTTPS_ONLY & HTTP_AND_HTTPS.
The valid values for hadoop.ssl.hostname.verifier are DEFAULT, STRICT,STRICT_I6, DEFAULT_AND_LOCALHOST and ALLOW_ALL. Only use ALLOW_ALL in a controlled environment & with caution. And then use ambari to restart all hdfs services.
Configure Knox to connect over SSL to WebHDFS
Make sure /etc/knox/conf/topologies/sandbox.xml (or whatever is the topology for your Knox deployment is) has a valid service address with HTTPS protocol to point to WebHDFS.
<service>
<role>WEBHDFS</role>
<url>https://workshop.hortonworks.com:50470/webhdfs</url>
</service>
Validate End to End SSL – Client > Knox > WebHDFS
curl -iku guest:guest-password -X GET 'https://workshop.hortonworks.com:8443/gateway/sandbox/webhdfs/v1/ op=LISTSTATUS'
SSL Between Knox & Oozie
By default, Oozie server runs with properties necessary for SSL configuration. For example,
do a ‘ps’ on your Oozie server (look for the process named Bootstrap) and you will see the following properties:
- -Doozie.https.port=11443
- -Doozie.https.keystore.file=/home/oozie/.keystore
- -Doozie.https.keystore.pass=password
You can change these properties with Ambari in Oozie server config in the advance oozie-env config section. I changed them to point the keystore file to /etc/oozie/conf/keystore.jks. For this blog, I re-used the keystore I created earlier for HDFS and copied /etc/security/serverKeys/keystore.jks to /etc/oozie/conf/keystore.jks
Configure Knox to connect over SSL to Oozie
Make sure /etc/knox/conf/topologies/sandbox.xml (if whatever is the topology for your Knox deployment is) has a valid service address with HTTPS protocol to point to Oozie.
<service>
<role>OOZIE</role>
<url>https://workshop.hortonworks.com:11443/oozie</url>
</service>
Validate End to End SSL – Client > Knox > Oozie
Apache Knox comes with a DSL client that makes operations against a Hadoop cluster trivial to use for exploration and one does not need to handle raw HTTP requests as I used in the previous examples.
Now run the following commands:
cd to /usr/lib/knox & java -jar bin/shell.jar samples/ExampleOozieWorkflow.groovy
Check out the /usr/lib/knox/samples/ExampleOozieWorkflow.groovy for details on what this script does.
Use higher strength SSL cipher suite
Often it is desirable to use a more secure cipher suite for SSL. For example, in the HDP 2.1 Sandbox, the cipher used for SSL between curl client and Knox in my environment is “EDH-RSA-DES-CBC3-SHA.”
JDK ships with ciphers that comply with US exports restricts and that limit the cipher strength. To use higher strength cipher, download UnlimitedJCE policy for your JDK vendor’s website and copy the files into the JRE. For Oracle JDK, you can get unlimited policy files from here.
cp UnlimitedJCEPolicy/* /usr/jdk64/jdk1.7.0_45/jre/lib/security/
If you use Ambari to setup your Hadoop cluster, you already have highest strength cipher allowed for the JDK, since Ambari setups the JDK with unlimited strength JCE policy.
Optional: Verify higher strength cipher with SSLScan
You can use a tool such as OpenSSL or SSLScan to verify that now AES256 is used for SSL.
For example, the command:
openssl s_client -connect localhost:8443
will print the cipher details:
New, TLSv1/SSLv3, Cipher is ECDHE-RSA-AES256-SHA384
Conclusion
SSL is the backbone of wire encryption. In Hadoop, there are multiple channels to move the data and access the cluster. This blog covered key SSL concepts and walked through steps to configure a cluster for end-to-end SSL. These steps are validated on a single node Hadoop cluster. Following these instructions for a multi-node Hadoop cluster will require a few more steps.
This blog covered a lot of ground, and I want to thank my colleague Sumit Gupta for his excellent input. Please let me know you have questions or comments.
The post End to End Wire Encryption with Apache Knox appeared first on Hortonworks.
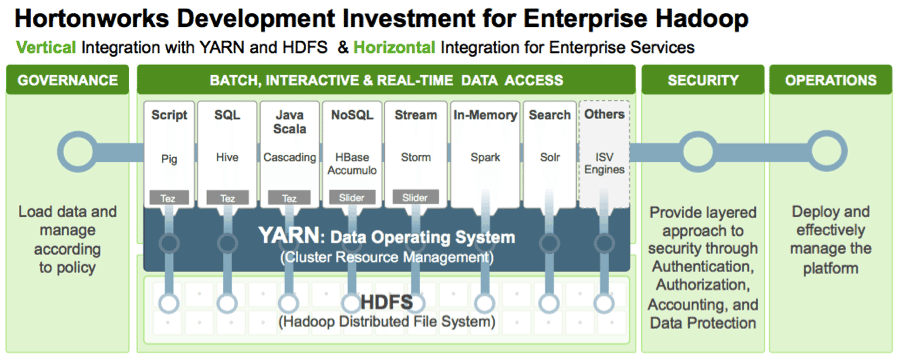
 We are in the midst of a data revolution. Hadoop, powered by Apache Hadoop YARN, enables enterprises to store, process, and innovate around data at a scale never seen before making security a critical consideration. Enterprises are looking for a comprehensive approach to security for their data to realize the full potential of the Hadoop platform unleashed by YARN, the architectural center and the data operating system of Hadoop 2.
We are in the midst of a data revolution. Hadoop, powered by Apache Hadoop YARN, enables enterprises to store, process, and innovate around data at a scale never seen before making security a critical consideration. Enterprises are looking for a comprehensive approach to security for their data to realize the full potential of the Hadoop platform unleashed by YARN, the architectural center and the data operating system of Hadoop 2.