Over the past two quarters, Hortonworks has been able to attract over 200 new customers. We are attempting to feed the hunger our customers have shown for Hadoop over the past two years. We are seeing truly transformational business outcomes delivered through the use of Hadoop across all industries. The most prominent use cases are focused on:
- Data Architecture Optimization – keeping 100% of the data at up to 1/100th of the cost while enriching traditional data warehouse analytics
- A Single View of customers, products, and supply chains
- Predictive Analytics – delivering behavioral insight, preventative maintenance, and resource optimization
- Data Discovery – exploring datasets, uncovering new findings, and operationalizing insights
What we have consistently heard from our customers and partners, as they adopt Hadoop, is that they would like Hortonworks to focus our engineering activities on three key themes: Ease of Use, Enterprise Readiness, and Simplification. During the first half of 2015, we made significant progress on each of these themes and we are ready to share the results. Keep in mind there is much more work to be done and we plan on continuing our efforts throughout the remainder of 2015.
Today Hortonworks proudly announces Hortonworks Data Platform 2.3 – which delivers a new breakthrough user experience along with increased enterprise readiness across security, governance, and operations. In addition, we are enhancing our support subscription with a new service called Hortonworks® Smartsense™
Breakthrough User Experience
HDP 2.3 eliminates much of the complexity administering Hadoop and improves developer productivity.
Hortonworks has been leading a truly Open Source and Open Community effort to put a new face on Hadoop, with the goal of eliminating the need for any cluster administrator, developer, or data architect to interact with a command-line interface (CLI). I know there are folks who love their CLI tools and I’m not saying that we should deprecate and remove those, but there are a large number of potential Hadoop users who would prefer to interact with the cluster entirely through a browser.
We actually started this effort with the introduction of Ambari 1.7.0, which delivered an underlying framework to support the development of new Web-based Views. We’ve built on that progress, leveraging the Views framework to deliver a breakthrough user experience for both Hadoop operators and developers. Here are some of the details…
Smart Configuration
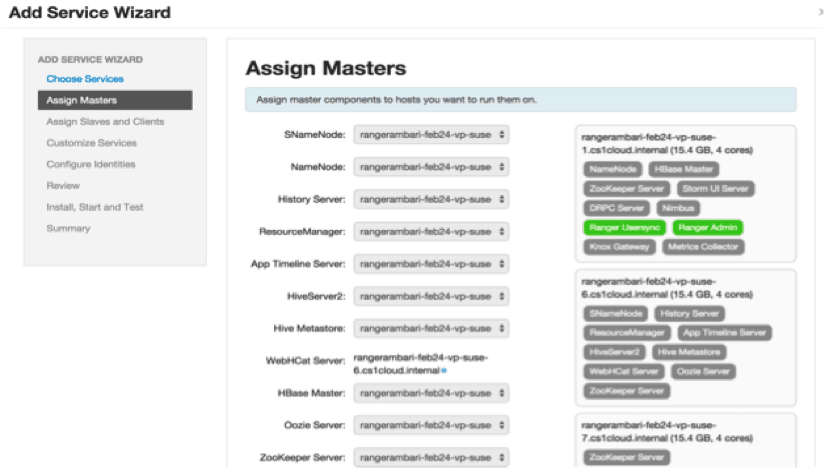
We have worked to develop two critical new capabilities for the Hadoop operator. The first is Smart Configuration. For configuration of HDFS, YARN, HBase, and Hive, we have provided an entirely new user experience within Apache Ambari. It is guided, opinionated (in a good way), and more digestible than ever before.
![hdp2.3_1]()
Our customers have told us that this approach is a giant leap forward from previous approach of configuring these parameters, and we hope you agree. For those experts out there, don’t worry, we still allow you to change, configure, and manipulate all of your favorite settings (which may not appear here) via the Advanced tab. But Smart Configuration provides a much simpler way to configure the most critical and frequently used parameters.
YARN Capacity Scheduler
With the introduction of Hadoop 2, YARN was introduced along with a new pluggable scheduler known as Capacity Scheduler. The Capacity Scheduler allows for multiple-tenants to securely share a large cluster such that their applications are allocated resources in a timely manner under constraints of allocated capacities. As organizations embrace the concept of a data lake which may support datasets and work loads from many different teams or parts of their organization, Capacity Scheduler allows the Hadoop operator to define minimum capacity guarantees within the cluster while each organization can access any excess capacity not being used by others. This approach ultimately provides cost-effective elasticity and ensures service-level agreements can be met for the queries, jobs, and tasks being run on Hadoop.
However, it can be complex to configure the Capacity Scheduler, and it requires manipulation of a fairly sophisticated XML document. The new experience delivers a user interface with sliders to scale values (very similar to how you might manage allocations to your retirement accounts). It delivers a dramatically simpler way to setup queues, and we believe that Hadoop operators will be thrilled with this new approach.
![hdp2.3_2]()
Customizable Dashboards
In addition to Smart Configuration, we also spent time sitting side-by-side with a number of our customers’ Hadoop operators to understand what kinds of dashboards and metrics they typically monitor as part of their job to maintain the overall health of their cluster.
Based on those experiences, we have developed customizable dashboards for a number of the most frequently requested components. Customizable dashboards allow each customer to develop a tailored experience for their environment and decide which metrics are most important to track visually.
Here is an example of an HDFS Dashboard in Ambari:
![hdp2.3_3]()
While we care very much about making the lives of Hadoop operators easier, what are we doing about for folks who write SQL queries, develop Pig Scripts, and develop data pipelines? How does HDP 2.3 make their lives easier?
We spent many hours partnering with developers and data stewards to answer those questions. We looked at the tools they currently use, listened to their requests, and started down the path of delivering a breakthrough experience for them in open source and within an open community – allowing others to contribute to this effort as well.
The initial focus was on the SQL developer and looking at the most common tasks they perform. Based on what we learned, we developed an integrated experience to:
- build SQL queries,
- provide a visual “explain plan,” and
- allow an extended debugging experience when using the Tez execution engine.
Here is a screenshot of what we’ve developed to make life easier for the SQL developer:
![hdp2.3_4]()
HDP 2.3 also provides a Pig Latin Editor that brings a modern browser-based IDE experience to Apache Pig. There is also a File Browser for HDFS and an entirely new user experience for Apache Falcon with a web-forms approach to rapidly develop feeds and processes. The new Falcon UI also allows you to search and browse processes that have executed, to visualize lineage and to setup mirroring jobs to replicate files and databases between clusters or to cloud storage such as Microsoft Azure Storage.
While we at Hortonworks have worked within the community to develop and advance these new user experiences, we are far from done. Some compelling new user experiences are still on the horizon, including a hosted version of Cloudbreak which will allow you to launch HDP into cloud-based environments and Apache Zeppelin (incubating) which provides a breakthrough user experience for Apache Spark. Stay tuned for more developments in this area.
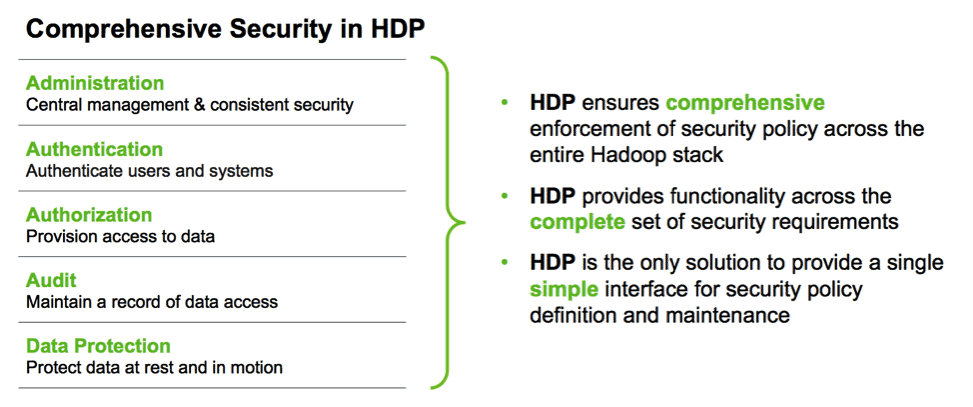
Enterprise Readiness: Enhancements to Security, Governance, and Operations
HDP 2.3 delivers new encryption of data-at-rest, extends the data governance initiative with Apache Atlas, and drives forward operational simplification for both on-premise and cloud-based deployments.
Before we go into the details on Security, Governance, and Operations, I want to highlight a couple of critical additions in HDP 2.3.
YARN continues to be the architectural center of Hadoop and HDP 2.3 provides a technical preview of the Solr search engine running on YARN. As we work within the community to harden and complete this critical advancement for search over big data, it will allow customers to reduce their total cost of ownership by deploying Apache Solr within the same cluster as their other workloads – eliminating the need for a “side cluster” dedicated to indexing data and delivering search results. We encourage customers to try this in their non-production clusters and provide feedback on their experience. Thanks to the team at Lucidworks for making this happen and working with us to do this via Apache Slider!
Another important new capability is high availability (HA) configuration options for Apache Storm, Apache Ranger, and Apache Falcon that power many mission-critical applications and services. Each of these components now provides an HA configuration to support business continuity when failures occur.
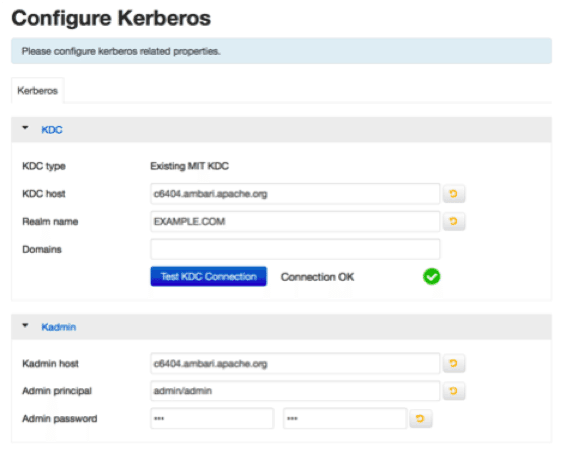
HDP 2.3 delivers a number of significant security enhancements. The first is HDFS Transparent Data at Rest Encryption. This is a critical feature for Hadoop and we have been performing extensive testing with our customers as part of an extended technical preview.
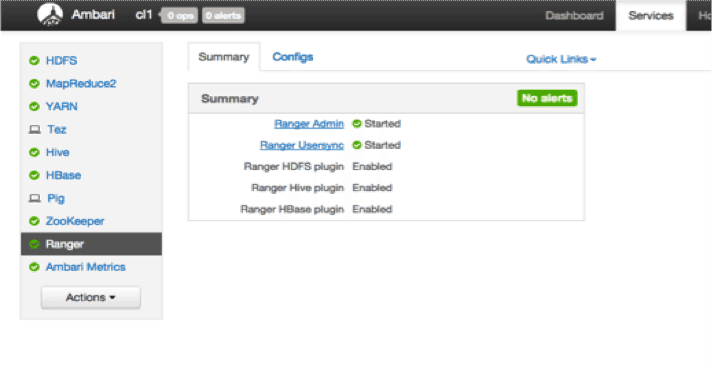
As part of providing support for HDFS Transparent Data at Rest Encryption, Apache Ranger provides a key management service (KMS) that leverages the Hadoop Key Provider API and it can provides a central key service for Hadoop.
![hdp2.3_5]()
There is more work to be done related to encrypting data at rest, but we feel confident customers can already adopt a core set of security use cases. We will continue to expand the capabilities and eliminate some remaining limitations over the coming months.
Other important addition to Apache Ranger included centralized authorization for Apache Solr, Apache Kafka and YARN. Security administrators can now define and manage security policies and capture security audit information for HDFS, Hive, HBase, Knox, and Storm along with Solr, Kafka and YARN.
On the auditing front, Ranger now supports using Solr as the backend for indexing the audit information and serving real-time query results. The Ranger team has also optimized audit data to summarize audit at the source, reducing audit noise and volume.
This screen shot gives you the sense for that simplification:
![hdp2.3_6]()
For the partner ecosystem, we have been thrilled by the success of Ambari Stacks and the extensibility and flexibility it provided.
As we look to fuel an ever-expanding partner ecosystem, we decided to take a page out of the Ambari extensibility guide and apply it to both Apache Ranger and Apache Knox. In HDP 2.3, Ranger and Knox both provide the ability for partners to define a “stack”. The stack definition allows partners to leverage Ranger’s centralized authorization and auditing capabilities and Knox’s API gateway capabilities without extensive coding.
Hortonworks believes in this kind of open and extensible approach as the best way to maximize the value for both our partners and customers. Expect to see the proof of this in the coming months.
Shifting to data governance, we launched the Data Governance Initiative (DGI) in January of 2015 and then delivered the first set of technology along with an incubator proposal to the Apache Software Foundation in April. HDP 2.3 delivers the core set of metadata services as an outcome of this effort.
This is really the first step on a journey to address data governance in a holistic way for Hadoop. Some of these initial capabilities will ease data discovery with a focus on Hive and establish a strong foundation for future feature additions as we look to tackle Kafka, Storm, and integrating dynamic security policies based on the available metadata tags.
In addition to the new user interface elements described earlier, Apache Falcon also enables Apache Hive database replication in HDP 2.3. Previously, Falcon provided support for replication of files (and incremental Hive partitions) between clusters, primarily to support disaster recovery scenarios. Now customers can use Falcon to replicate Hive databases, tables and their underlying metadata–complete with bootstrapping and reliably applying transactions to targets.
Finally on to operations. The pace of innovation in Apache Ambari continues to astonish. As part of HDP 2.3, Ambari supports a significantly wider range of component deployment and monitoring than ever before. This includes the ability to install and manage: Accumulo, Atlas, DataFu, Mahout, and the Phoenix Query Server (in Tech Preview). It also includes an extended ability to configure the NFS Gateway of HDFS. In addition, Ambari now provides support for rack awareness–allowing you to define and manage your data topology by rack.
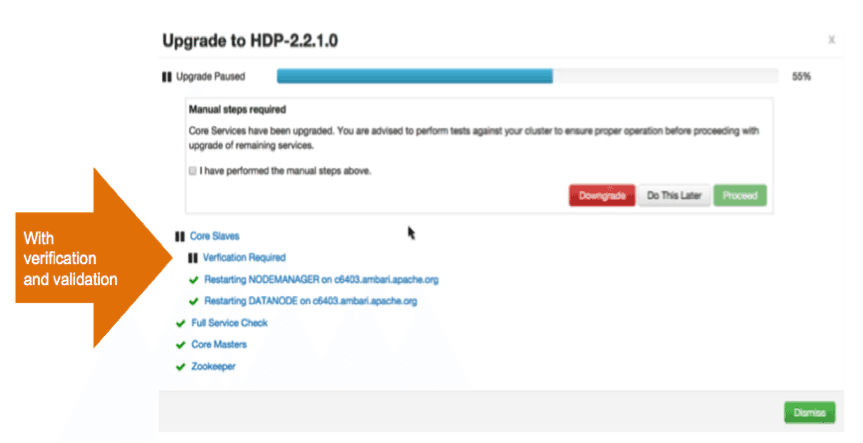
We introduced the automation for rolling upgrade as part of Ambari 2.0, but this was primarily focused on automating the application of maintenance releases to your running cluster. Now, Ambari expands its reach to support rolling upgrade for feature bearing releases as well. This automates your ability to roll from HDP 2.2 to HDP 2.3.
Following the general availability of HDP 2.3, Cloudbreak will also become generally available. Since Hortonworks’ acquisition of SequenceIQ, the integrated team has been working hard to complete the deployment automation for public clouds including Microsoft Azure, Amazon EC2, and Google Cloud. Our support and guidance will be available to all Hortonworks customers who have an active Enterprise Plus support subscription.
![hdp2.3_7]()
Proactive Support with Hortonworks SmartSense™
In addition to all of the tremendous platform innovation, Hortonworks is proud to announce Hortonworks SmartSense™, which adds proactive cluster monitoring and delivers critical recommendations to customers who opt into this extended support capability.
The addition of Hortonworks SmartSense further enhances Hortonworks’ world-class support subscriptions for Hadoop.
To adopt Hortonworks SmartSense our customers can simply download the Hortonworks Support Tool (HST) from the support portal and deploy it to their cluster. HST then collects configuration and other operational information about their HDP cluster and packages it up into a bundle.
After uploading this information bundle to the Hortonworks’ support team, we use our own HDP cluster to analyze all the information it provides. It performs more than 80 distinct checks across the underlying operating system, HDFS, YARN, MapReduce, Tez, and Hive components.
![hdp2.3_8]()
Hortonworks SmartSense then delivers the results of the analysis in the form of recommendations to customers via the support portal. Feedback from our customers who have tried beta versions of SmartSense has been tremendously positive, and we believe there is much more we can do to expand this capability.
For example, we plan to integrate the service with Apache Ambari, so that our subscribers can receive recommendations as “recipes” that can be directly applied to the cluster. We also believe that additional predictions on capacity planning and tuning for maximum cluster resource utilization can be delivered via SmartSense.
This is an example of the Hortonworks SmartSense user interface:
![hdp2.3_9]()
Of course, there is so much more that I didn’t cover here which is also part of HDP 2.3! There has been meaningful innovation within Hive for supporting Union within queries and using interval types in expressions, additional improvements for HBase and Phoenix, integration of Solr with Storm and HBase to enable near real-time indexing, and more. But, for now, I’ll leave those for subsequent blog posts that will highlight them all in more detail.
In closing, I would like to thank the entire Hortonworks team and the Apache community for the hard work they put in over the past six to eight months. That hard work set the stage for the enterprises adopting Open Enterprise Hadoop for the first time, as much as it will delight those who have been using Hadoop for years.
HDP 2.3 Resources
The post Hortonworks Data Platform 2.3 – Delivering Transformational Outcomes appeared first on Hortonworks.
 This blog gives an overview of these new features and how they integrate with other Hadoop services. We’ll also touch on additional innovation we plan for upcoming releases.
This blog gives an overview of these new features and how they integrate with other Hadoop services. We’ll also touch on additional innovation we plan for upcoming releases.






















 Matthew Morgan is the vice president of global product marketing for Hortonworks. In this role, he leads Hortonworks product marketing, vertical solutions marketing, and worldwide sales enablement. His background includes twenty years in enterprise software, including leading worldwide product marketing organizations for Citrix, HP Software, Mercury Interactive, and Blueprint. Feel free to connect with him on
Matthew Morgan is the vice president of global product marketing for Hortonworks. In this role, he leads Hortonworks product marketing, vertical solutions marketing, and worldwide sales enablement. His background includes twenty years in enterprise software, including leading worldwide product marketing organizations for Citrix, HP Software, Mercury Interactive, and Blueprint. Feel free to connect with him on 


